AI
AI-assisted Cassandra operations
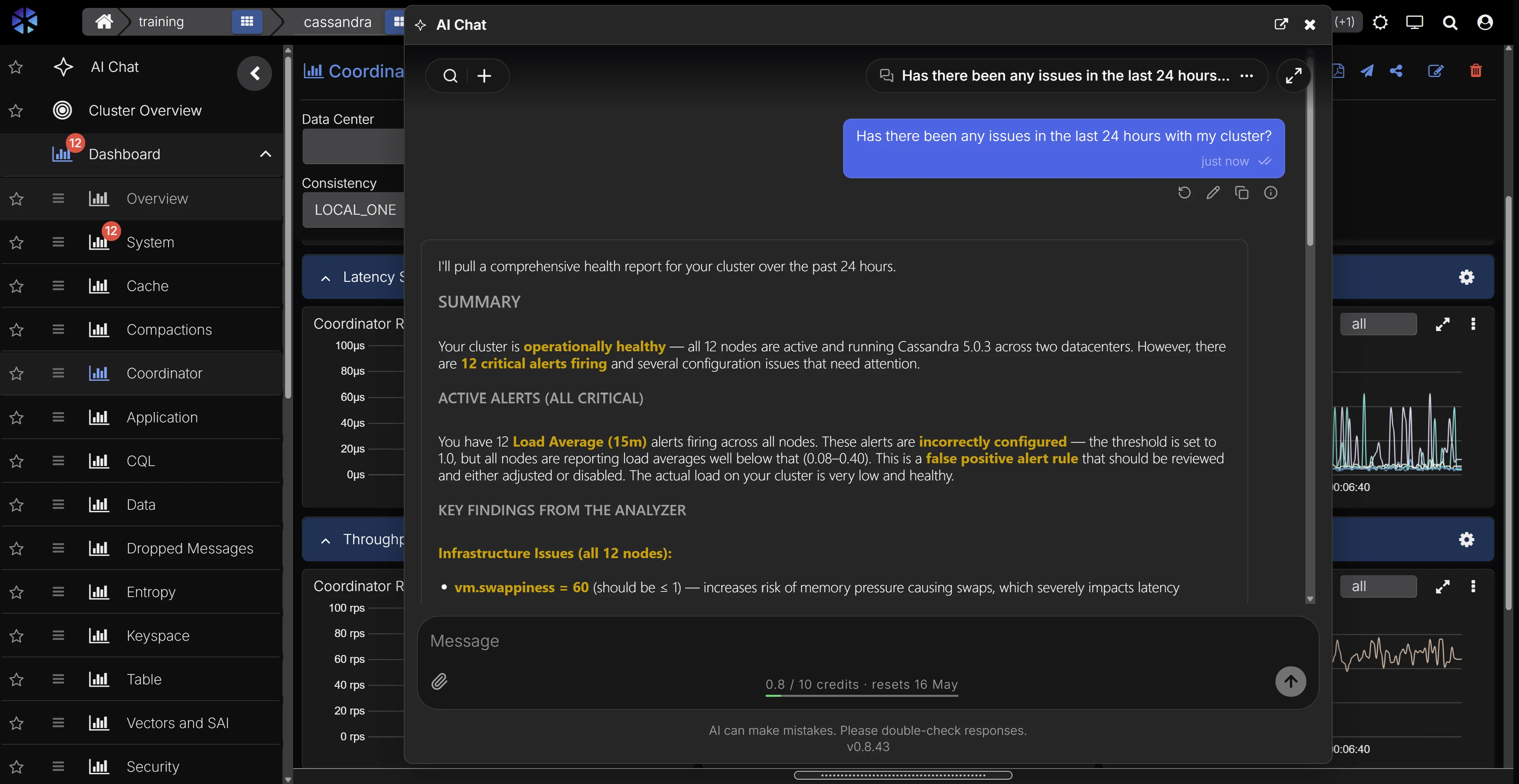
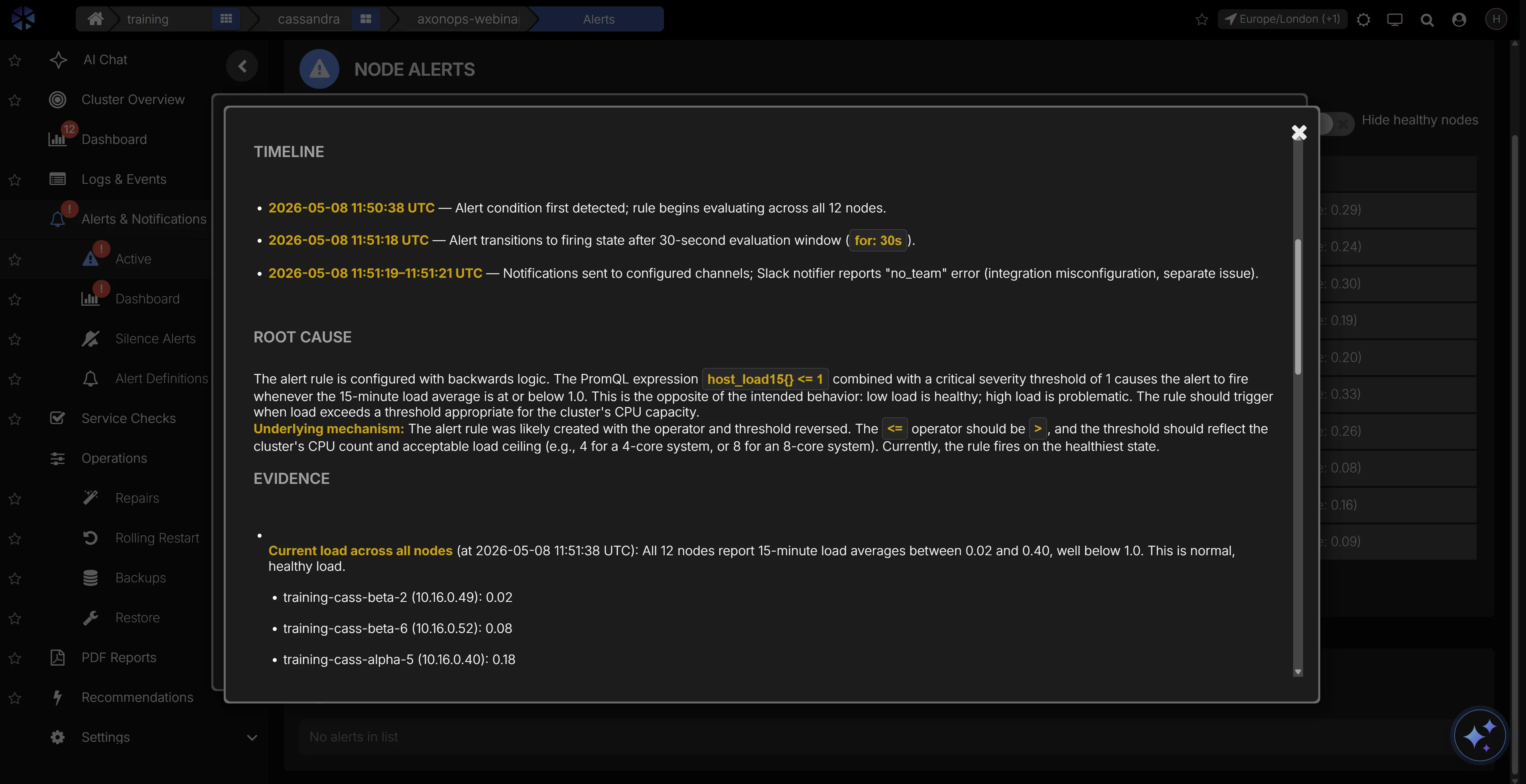
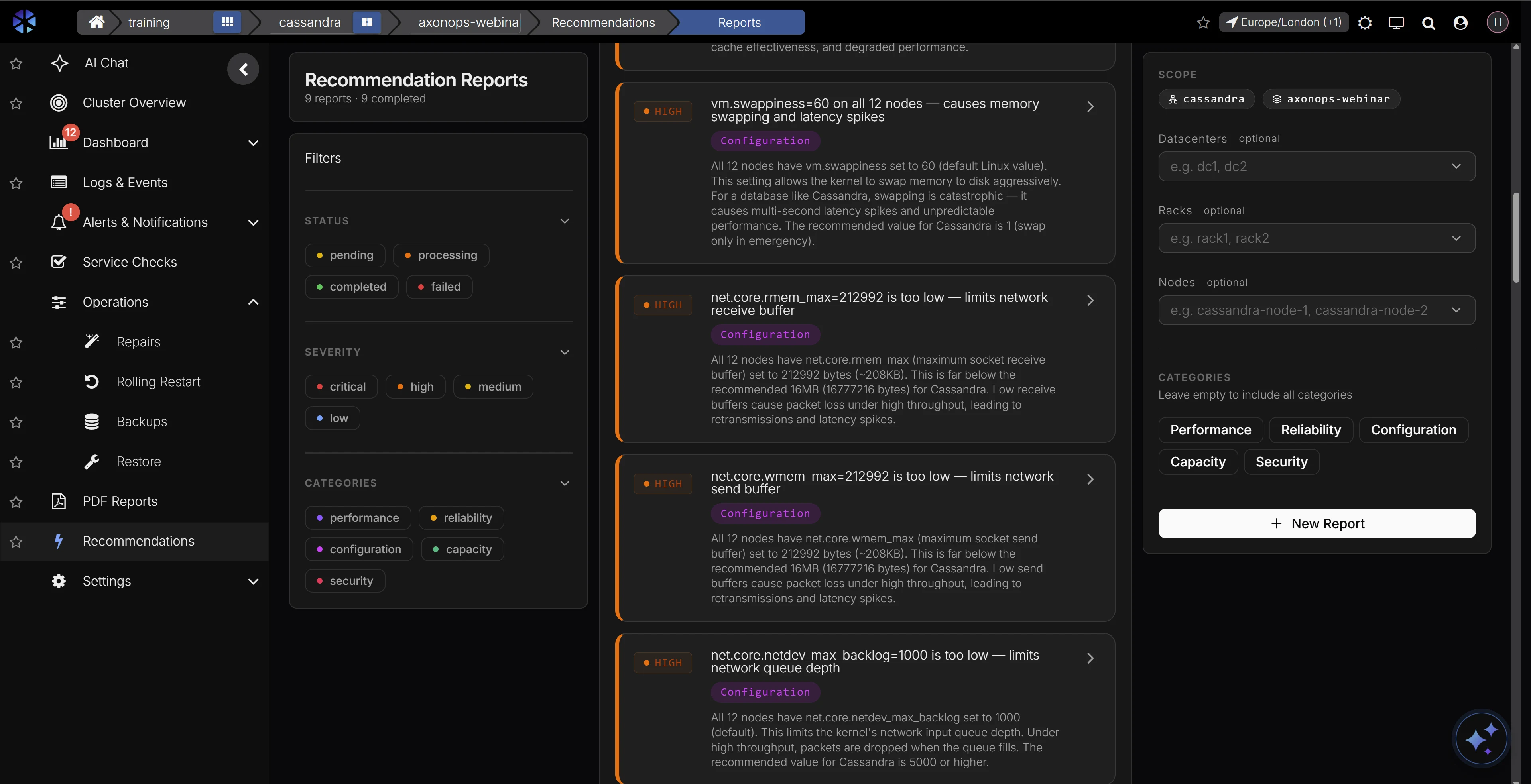
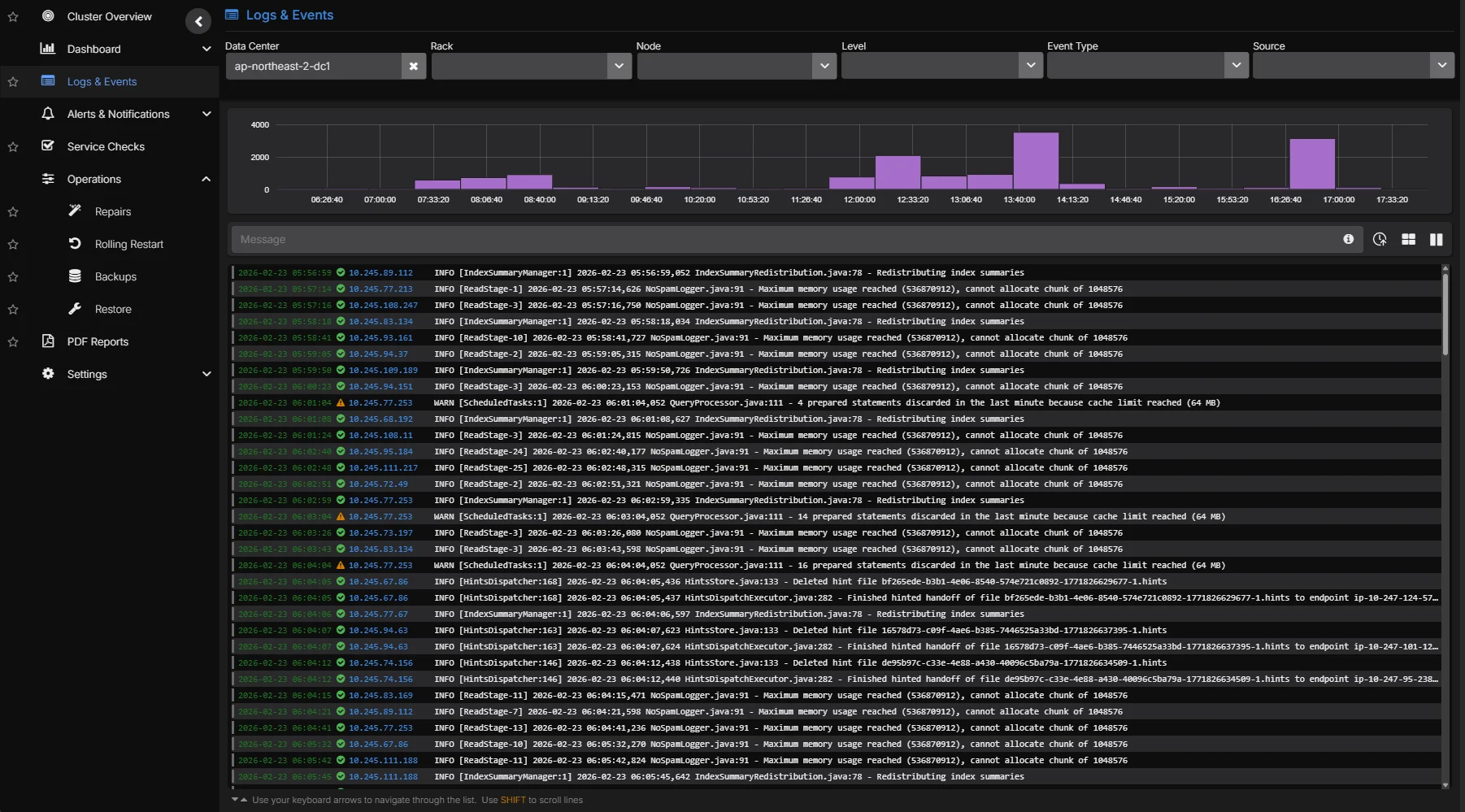
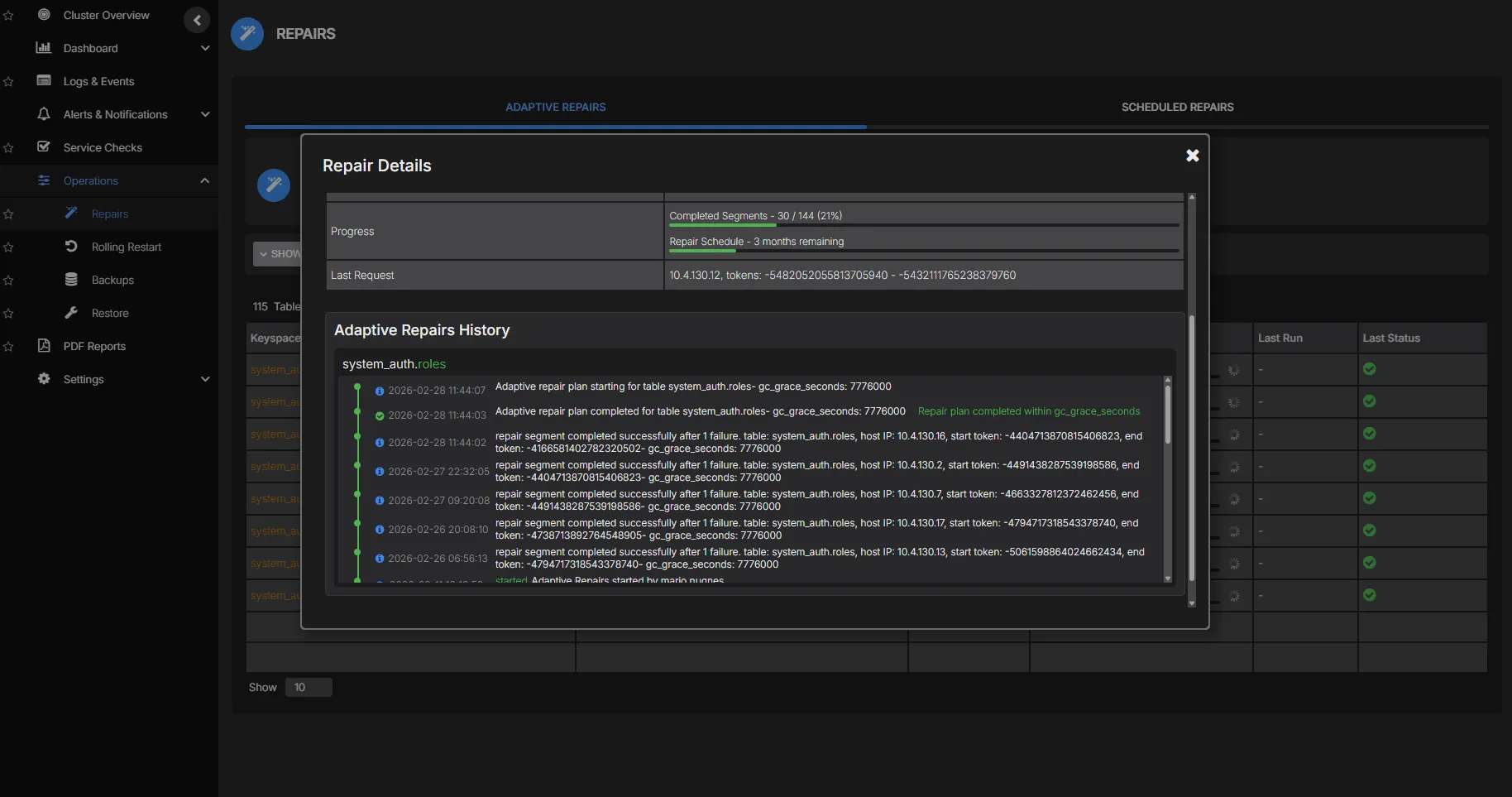
Ask questions in natural language and get answers backed by your live cluster state. AI-assisted analysis reasons over your metrics, logs, and configuration, with deep training on Cassandra source code and documentation, so responses reflect how Cassandra actually behaves instead of generic advice.
- Natural-language chat over live metrics, logs, and cluster configuration
- AI-assisted root cause analysis that shortens MTTR for on-call engineers
- AI trained on Cassandra source code and documentation
- AI-guided investigation grounded in live cluster context